Today, we are excited to announce the release of Stable Video Diffusion, our inaugural foundation model for generative video. Built on the capabilities of the popular image model Stable Diffusion, this state-of-the-art video model is now available in research preview.
This marks a major milestone in our mission to develop accessible generative AI tools for all types of users.
Research Release Details
As part of this research-focused release, we have made the Stable Video Diffusion code accessible via our GitHub repository. Additionally, the model weights required for local execution are available on our Hugging Face page. For an in-depth look at the technical details, you can refer to our research paper.
Versatility Across Video Applications
Our video model is designed with adaptability in mind and can be customized for a wide range of video-related tasks. For example, it enables multi-view synthesis from a single image when fine-tuned on relevant datasets. This flexibility paves the way for future models that expand on this foundation, much like the ecosystem that has evolved around Stable Diffusion.
Performance That Stands Out
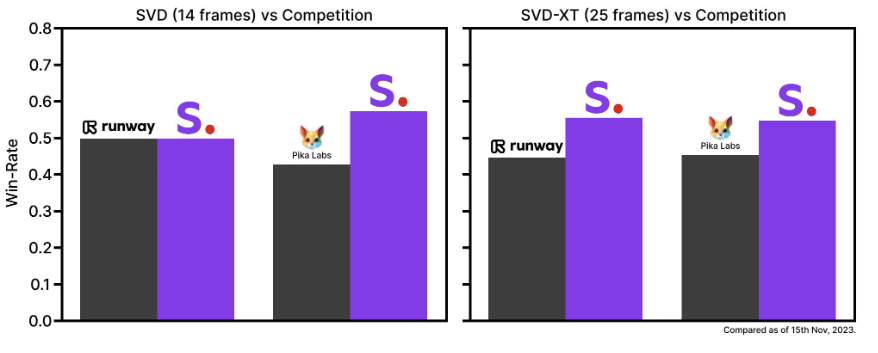
At launch, Stable Video Diffusion includes two image-to-video models, capable of generating sequences of 14 or 25 frames. Users can customize the frame rate, choosing anywhere between 3 and 30 frames per second.
Initial external evaluations reveal that these models outperform leading closed alternatives in user preference studies, showcasing their competitive edge.
A Model Exclusively for Research
While we remain committed to advancing and refining our models, we emphasize that this version of Stable Video Diffusion is not intended for real-world or commercial use at this stage. Your feedback on safety and quality will play a vital role in shaping future iterations and ensuring a robust eventual release.
This approach aligns with our prior releases in emerging modalities, and we’re eager to share more developments as they unfold.
Expanding Our AI Model Ecosystem
Stable Video Diffusion joins Stability AI’s growing suite of open-source models, spanning diverse modalities such as image, language, audio, 3D, and code. This portfolio reflects our unwavering commitment to amplifying human creativity and intelligence through accessible and powerful AI tools.








































































































Validate your login
Sign In
Create New Account