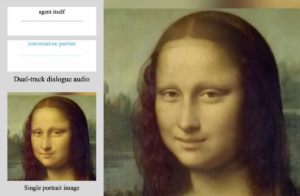
ByteDanced introduced INFP, an advanced audio-driven interactive head generation framework designed for dyadic conversations. Utilizing dual-track audio inputs and a single portrait image of any agent, our system generates dynamic agent videos with realistic facial expressions, natural head movements, and synchronized verbal and non-verbal behaviors. Its sophisticated yet lightweight design makes INFP ideal for instant communication applications such as video conferencing, online education, and virtual assistants.
The acronym INFP stands for Interactive, Natural, Flash, and Person-generic, highlighting the system’s key attributes. Imagine engaging in a conversation with a socially intelligent agent that listens attentively, responds visually and verbally, and supports fluid, multi-turn interactions. This seamless conversational experience forms the foundation of our framework.
Key Features
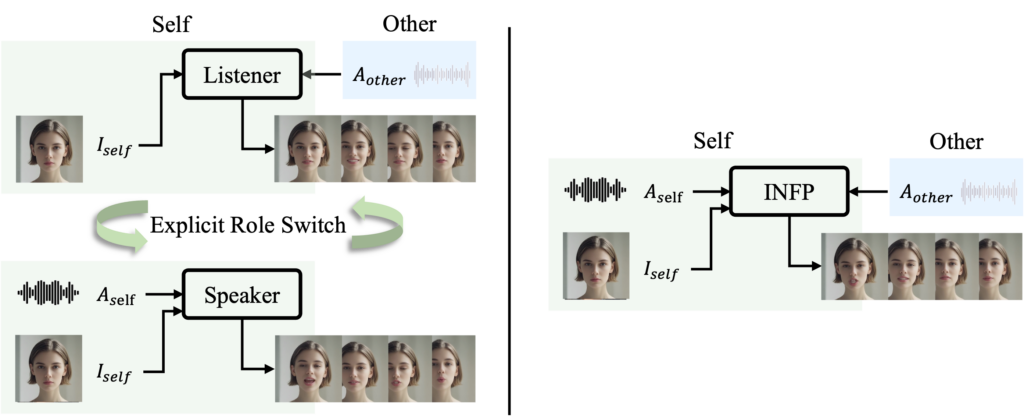
Unlike previous head generation models limited to one-sided communication or requiring manual role assignment, INFP offers automatic role alternation between speaking and listening states based entirely on dyadic audio input. This enables more dynamic and contextually appropriate interactions.
Framework Structure
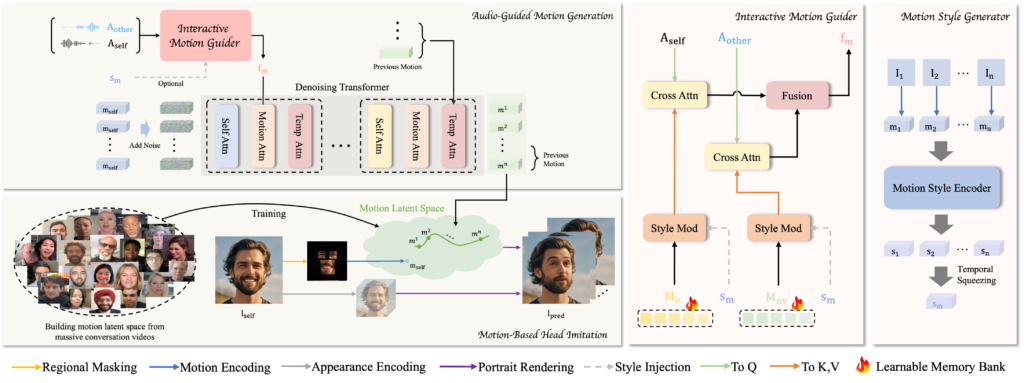
INFP comprises two main stages:
Motion-Based Head Imitation: This stage learns to translate facial communicative behaviors from real-life conversation videos into a low-dimensional motion latent space. These motion codes animate a static portrait image, capturing expressive facial gestures and head movements.
Audio-Guided Motion Generation: This stage maps dyadic audio inputs to motion latent codes using a denoising process, enabling real-time, audio-driven head animation in interactive settings.
Dataset and Evaluation
To advance research in this area, we introduce DyConv, a comprehensive dataset of diverse dyadic conversations sourced from the Internet. Extensive experiments and visual analyses demonstrate the superior performance and adaptability of INFP. The framework naturally supports related tasks such as talking and listening head generation without requiring additional adjustments.
Technical Advantages
Scalability: INFP efficiently scales across various application domains, including remote collaboration, virtual reality, and AI-powered customer support.
Versatility: Its modular design allows seamless integration with existing conversational AI platforms.
Performance: Evaluations reveal high lip-sync accuracy, expressive facial modeling, and smooth head pose adjustments synchronized with audio input.
Application Highlights
Talking Head Generation: INFP excels at generating videos with precise lip-sync, expressive facial cues, and realistic head pose movements aligned with speech dynamics.
Interactive Head Generation: Unlike traditional methods requiring manual role-switching between speakers and listeners, INFP dynamically adapts to role changes, ensuring continuous and natural interactions.
Future Prospects: Potential applications include interactive digital avatars, remote learning platforms, and immersive virtual environments where natural and responsive agent interactions are essential.
Overall, INFP represents a significant leap in audio-driven interactive head generation, combining technological sophistication with practical usability in real-world communication scenarios.








































































































Validate your login
Sign In
Create New Account